在 Windows 系统中,SpaceSniffer 和 TreeSize Free 是分析磁盘空间的得力助手,能让我们轻松掌握磁盘的存储情况。但对于 Linux 用户来说,通常只能手动组合 du、find 等命令来排查大文件,操作起来颇为繁琐。不过今天,我们要给大家带来一个好消息 —— 一款纯 Bash 脚本工具横空出世,它不仅能实现类似 Windows 工具的功能,甚至更加强大!
✅ 强大功能,一应俱全
这款脚本工具具备多种实用功能,满足你对磁盘分析的各种需求:
•
递归扫描大目录:支持 T/G/M 等常见存储单位,能精准扫描指定大小的目录。
智能层级排序:通过 dirname 提取父目录,确保像 /a/b 这样的目录始终在 /a/b/c 之前显示,同层级目录还会按大小降序排列,避免显示杂乱。 交互式序号选择:输入数字就能直接进入子目录,无需记忆复杂路径,像操作文件管理器一样简单。 小文件智能折叠:对于过多的小文件(如日志目录),会自动折叠,同时显示总数以及最早、最晚创建时间,让信息展示更简洁明了。
? 脚本核心功能及参数说明
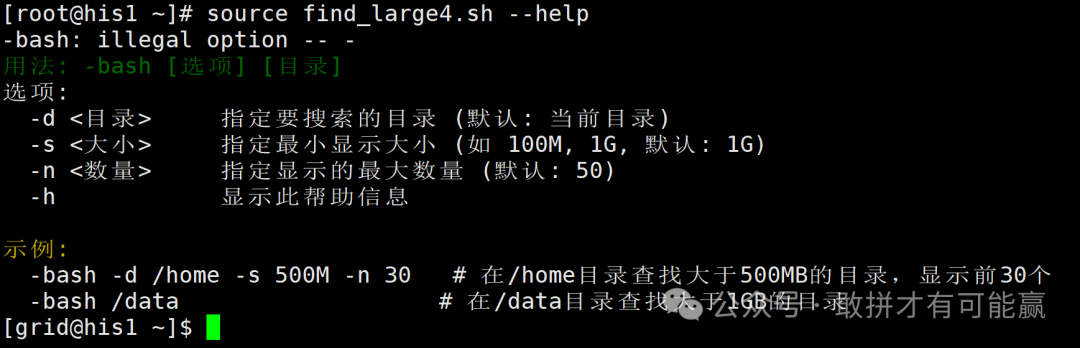
运行脚本的命令格式如下:
./diskanalyzer.sh -d / -s 1G -n 20
参数说明:
•
-d:扫描目录,默认是 /。
-s:最小文件大小,例如 1G、500M 等。-n:最大显示数量。
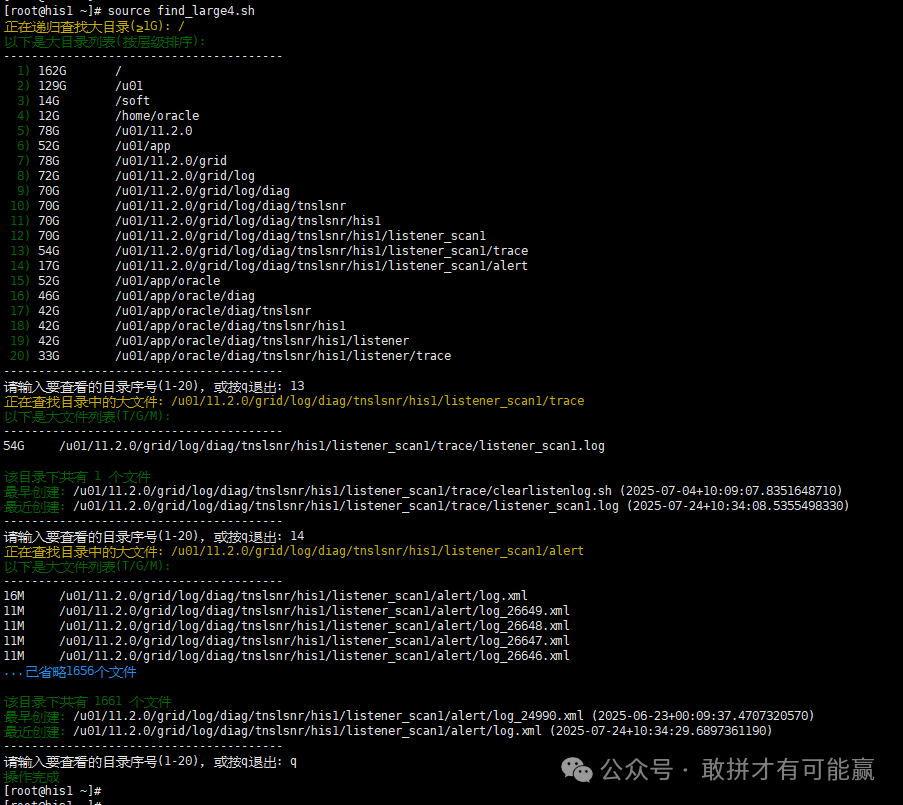
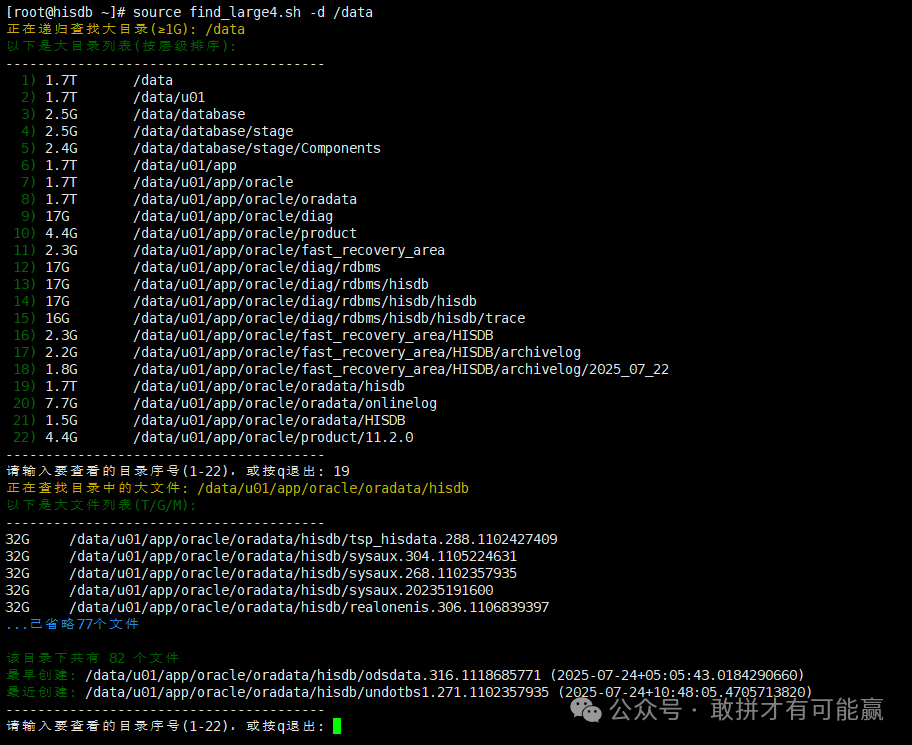
示例输出:
正在扫描大目录(≥1G): /\---------------------------------------- 1) 162G / 2) 129G /u01 3) 78G /u01/11.2.0 4) 78G /u01/11.2.0/grid 5) 72G /u01/11.2.0/grid/log ...\----------------------------------------输入序号查看子目录,或按 q 退出: 3
选择目录后,会显示该目录下的详情:
/u01/11.2.0 下的大文件:\----------------------------------------45G oracle\_installer.bin 12G patch\_set.zip ...已省略 8 个文件 该目录共有 10 个文件 最早创建: backup\_2022.tar (2022-11-01) 最近修改: installer.log (2023-06-15) \----------------------------------------
? 技术亮点,优势凸显
智能层级排序
运用 dirname 提取父目录,保证目录展示的有序性,同层级按大小降序排列,让你一眼看清存储分布。
交互式探索
就像操作文件管理器一样,输入数字就能 “进入” 子目录,无需费力记忆路径,操作便捷高效。
小文件优化
对于日志目录等小文件过多的情况,会自动折叠,同时显示总数和时间范围,既不占用过多篇幅,又能让你了解关键信息。
? 选择这款脚本的理由
•
比原生命令更直观:不用再手动组合 du -h --max-depth=1 | sort -rh 等命令,省去繁琐操作。
比 GUI 工具更灵活:纯命令行实现,即使通过 SSH 连接远程服务器也能轻松使用。 开源可定制:可以自由调整显示数量、排序规则等,满足个性化需求。
? 获取脚本
只需按照将以下代码复制到linux脚本文件即可
#!/bin/bash# 递归查找大目录并支持序号选择的脚本(完整版)
? 适用场景
•
快速定位日志膨胀问题,如 Docker、MySQL 日志等。
清理老旧服务器上的残留文件,如临时安装包。 分析 NAS 存储分布,按目录统计占用情况。
如果你是 Linux 运维人员或开发者,这款脚本绝对会成为你的得力新宠!
立即尝试,并在评论区分享你的使用体验吧!
#Linux #运维
#Bash 脚本
#磁盘分析
#开源工具
# 默认设置
DEFAULT_DIR="." # 默认搜索当前目录DEFAULT_MIN_SIZE="1G" # 默认显示大于等于1GB的目录DEFAULT_TOP_N=50 # 默认显示数量MAX_SMALL_FILES=5 # 小文件最大显示数量# 颜色定义RED='\033[0;31m'GREEN='\033[0;32m'YELLOW='\033[0;33m'BLUE='\033[0;34m'NC='\033[0m' # No Color# 显示帮助信息show_help() {echo -e "${GREEN}用法: $0 [选项] [目录]${NC}"echo "选项:"echo " -d <目录> 指定要搜索的目录 (默认: 当前目录)"echo " -s <大小> 指定最小显示大小 (如 100M, 1G, 默认: 1G)"echo " -n <数量> 指定显示的最大数量 (默认: 50)"echo " -h 显示此帮助信息"echo ""echo -e "${YELLOW}示例:${NC}"echo " $0 -d /home -s 500M -n 30 # 在/home目录查找大于500MB的目录,显示前30个"echo " $0 /data # 在/data目录查找大于1GB的目录"}# 解析命令行参数while getopts "d:s:n:h" opt; docase $opt ind) search_dir="$OPTARG" ;;s) min_size="$OPTARG" ;;n) top_n="$OPTARG" ;;h) show_help; exit 0 ;;*) show_help; exit 1 ;;esacdone# 处理位置参数(目录)shift $((OPTIND-1))if [ -n "$1" ]; thensearch_dir="$1"fi# 设置默认值(如果用户未指定)search_dir="${search_dir:-$DEFAULT_DIR}"min_size="${min_size:-$DEFAULT_MIN_SIZE}"top_n="${top_n:-$DEFAULT_TOP_N}"# 检查目录是否存在if [ ! -d "$search_dir" ]; thenecho -e "${RED}错误: 目录 '$search_dir' 不存在${NC}"exit 1fi# 将大小转换为KB以便比较size_to_kb() {local size=$1local unit=${size: -1}local num=${size%$unit}case $unit inT) echo "$num * 1024 * 1024 * 1024" | bc ;;G) echo "$num * 1024 * 1024" | bc ;;M) echo "$num * 1024" | bc ;;K) echo "$num" | bc ;;*) echo "$num / 1024" | bc ;; # 无单位默认为字节esac}# 计算路径深度path_depth() {local path=$1echo "${path//[^\/]/}" | wc -c}# 获取原始的大目录列表get_raw_large_dirs() {local dir="$1"du -h --max-depth=10 "$dir" 2>/dev/null | \grep -E '[TGM]' | \sort -rh | \head -n "$top_n" | \awk -v min_size="$min_size" 'BEGIN {split("K M G T", units)}{size=$1# 提取数字和单位match(size, /^([0-9.]+)([KMGTP]?)/, arr)num=arr[1]unit=arr[2]# 转换为KB的比较基准if(unit == "T") factor=1024*1024*1024else if(unit == "G") factor=1024*1024else if(unit == "M") factor=1024else if(unit == "K") factor=1else factor=1/1024 # 无单位默认为字节,转换为KBsize_kb=num*factor# 解析用户指定的最小大小match(min_size, /^([0-9.]+)([KMGTP]?)/, min_arr)min_num=min_arr[1]min_unit=min_arr[2]if(min_unit == "T") min_factor=1024*1024*1024else if(min_unit == "G") min_factor=1024*1024else if(min_unit == "M") min_factor=1024else if(min_unit == "K") min_factor=1else min_factor=1/1024min_size_kb=min_num*min_factorif(size_kb >= min_size_kb) {printf "%s\t%s\n", $1, $2}}'}# 按层级排序并显示带序号的列表display_hierarchical_with_numbers() {local raw_list="$1"echo -e "${YELLOW}正在递归查找大目录(≥$min_size): $search_dir${NC}"echo -e "${GREEN}以下是大目录列表(按层级排序):${NC}"echo "----------------------------------------"# 重置目录数组DIR_ARRAY=()# 处理原始列表{# 读取所有行到数组declare -a lineswhile IFS=$'\t' read -r size path; do# 提取父目录(倒数第二级目录)parent=$(dirname "$path")# 计算路径深度depth=$(path_depth "$path")# 使用父目录、深度和大小作为排序键lines+=("${parent}|${depth}|${size}|${path}")done# 按父目录、深度和大小排序sorted_list=$(printf "%s\n" "${lines[@]}" | sort -t'|' -k1,1 -k2n -k3hr)# 显示带序号的列表local count=1while IFS='|' read -r parent depth size path; doprintf "${GREEN}%3d)${NC} %s\t%s\n" "$count" "$size" "$path"DIR_ARRAY[$count]="$path"((count++))done <<< "$sorted_list"} <<< "$raw_list"echo "----------------------------------------"}# 查看目录中的大文件(改进版)show_large_files() {local dir="$1"echo -e "${YELLOW}正在查找目录中的大文件: $dir${NC}"echo -e "${GREEN}以下是大文件列表(T/G/M):${NC}"echo "----------------------------------------"# 获取所有大文件files_list=$(find "$dir" -maxdepth 1 -type f -exec du -h {} + 2>/dev/null | grep -E '[TGM]' | sort -rh)# 计算文件总数total_files=$(echo "$files_list" | wc -l)if [ "$total_files" -gt $MAX_SMALL_FILES ]; then# 显示前N个最大的文件echo "$files_list" | head -n $MAX_SMALL_FILESecho -e "${BLUE}...已省略$(($total_files - $MAX_SMALL_FILES))个文件${NC}"elseecho "$files_list"fi# 显示文件总数echo -e "\n${GREEN}该目录下共有 ${total_files} 个文件${NC}"# 显示最早和最晚创建的文件oldest_file=$(find "$dir" -maxdepth 1 -type f -printf '%T+ %p\n' 2>/dev/null | sort | head -n 1)newest_file=$(find "$dir" -maxdepth 1 -type f -printf '%T+ %p\n' 2>/dev/null | sort -r | head -n 1)if [ -n "$oldest_file" ]; thenoldest_time=$(echo "$oldest_file" | awk '{print $1}')oldest_name=$(echo "$oldest_file" | cut -d' ' -f2-)echo -e "${GREEN}最早创建:${NC} $oldest_name (${oldest_time})"fiif [ -n "$newest_file" ]; thennewest_time=$(echo "$newest_file" | awk '{print $1}')newest_name=$(echo "$newest_file" | cut -d' ' -f2-)echo -e "${GREEN}最近创建:${NC} $newest_name (${newest_time})"fiecho "----------------------------------------"}# 主程序raw_list=$(get_raw_large_dirs "$search_dir")display_hierarchical_with_numbers "$raw_list"# 交互菜单while true; doread -p "请输入要查看的目录序号(1-${#DIR_ARRAY[@]}),或按q退出: " choiceif [[ "$choice" == "q" ]]; thenbreakelif [[ "$choice" =~ ^[0-9]+$ ]] && [ "$choice" -ge 1 ] && [ "$choice" -le ${#DIR_ARRAY[@]} ]; thenselected_dir="${DIR_ARRAY[$choice]}"show_large_files "$selected_dir"elseecho -e "${RED}错误: 请输入有效序号(1-${#DIR_ARRAY[@]})或q退出${NC}"fidoneecho -e "${GREEN}操作完成${NC}"
附:与其他工具对比

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://www.kinber.cn/post/5373.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: