DeepSeek-OCR已经出来好长时间了,一直没有时间来做下测试,这次抽空来测试下DeepSeek-OCR,看看DeepSeek-OCR效果如何。
本来想直接部署DeepSeek-OCR,部署完之后再写接口传图片调用来测试。
无意间发现了DeepSeek-OCR-WebUI,直接有现成的网页端,那就比较省事了,可以直接部署这个来测试。
而且DeepSeek-OCR-WebUI也为大家分好了好几种功能来调用DeepSeek-OCR,简直太贴心了。
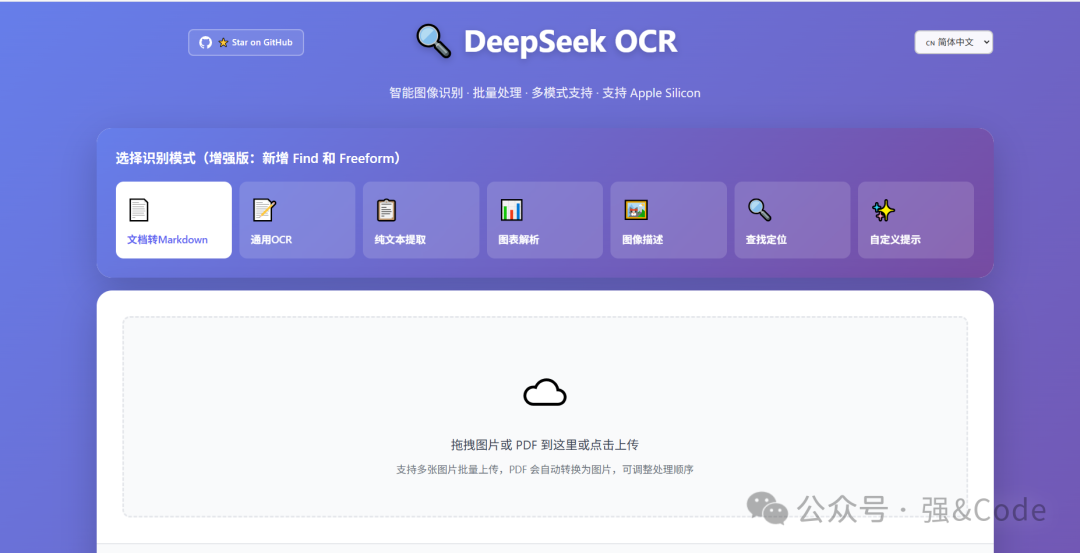
咱们现在开始。
1、部署环境。
1.1下载代码
git clone https://github.com/neosun100/DeepSeek-OCR-WebUI
支持源码部署和docker安装。
但是我测试的docker安装失败了,提升我nvidia-driver版本老了。

我的版本明明比较新的,而且又重新安装较新的驱动也还是报这次错,所以就直接放弃docker安装了,改用源码安装。
1.2 创建环境 安装基本环境
conda create -n deepseek-ocr-mlx python=3.11conda activate deepseek-ocr-mlxpip install -r requirements-mac.txt
2、安装torch
我的cuda是12.6的,所以安装的12.6版本的torch
3、启动
看GitHub上面有两种启动方式,第一种我启动没成功。
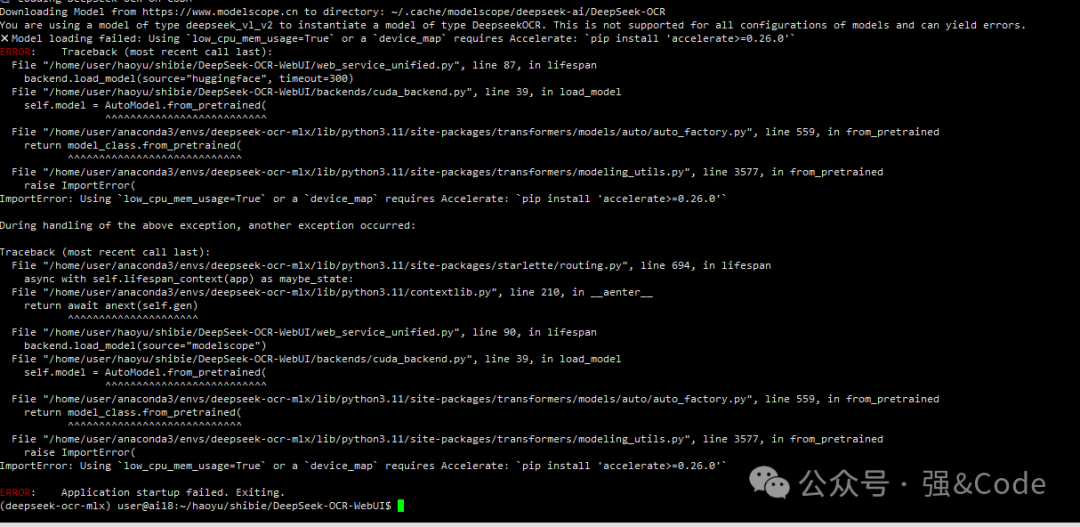
报错确实包,安装这个包后还报错。
选择用第二种,直接py文件启动。
python web_service_unified.py
最后用第二种方式启动成功了。浏览器打开:http://ip:8001
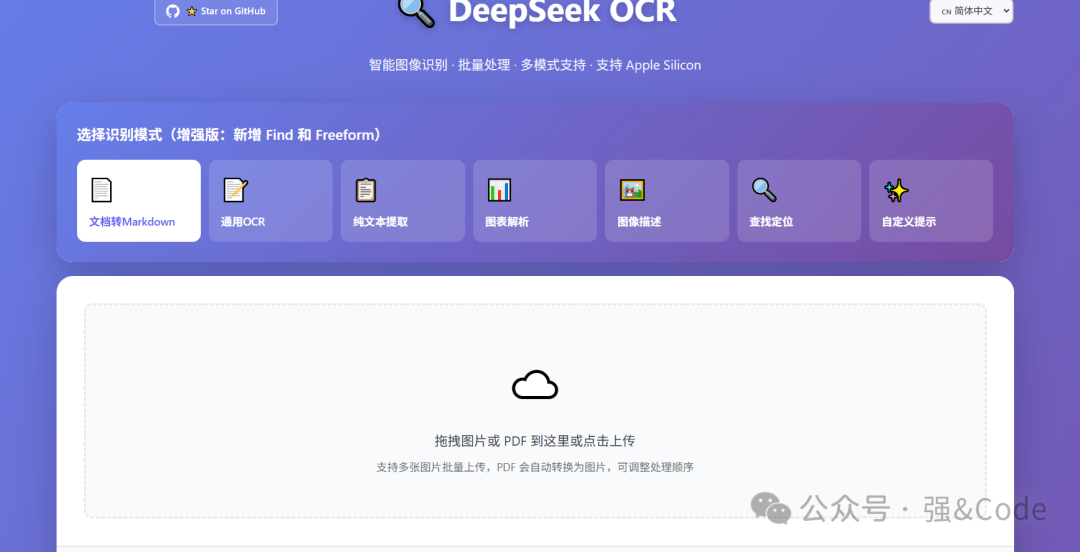
4、验证
DeepSeek-OCR真是强大,提供了文档转markdown、通用OCR、纯文本提取、图像解析、图片描述、查找定位等功能。
我先试试查找定位的功能。
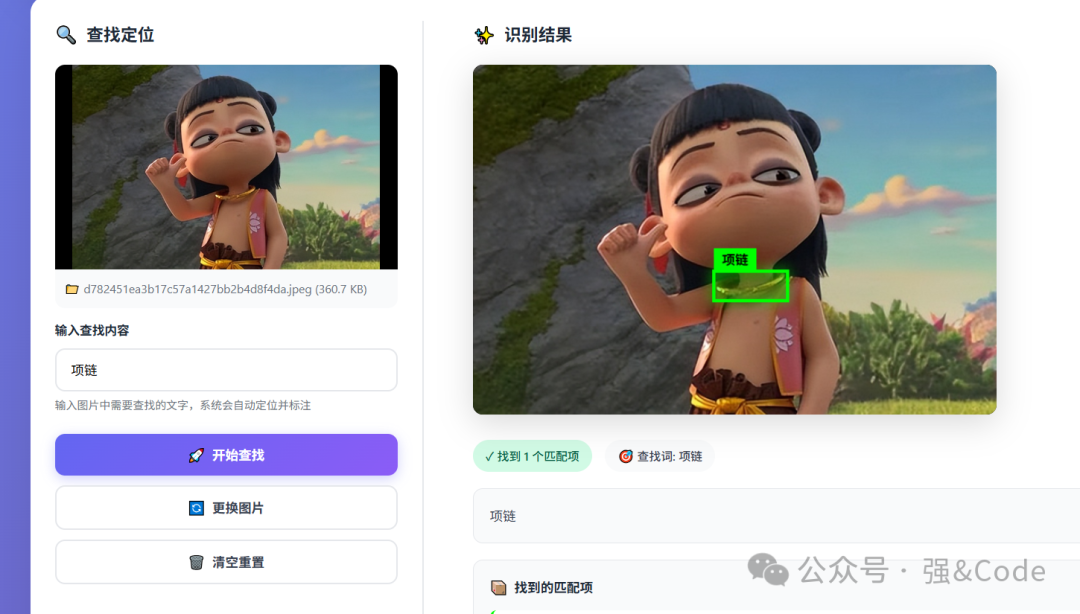
看着效果不错,再试一张。
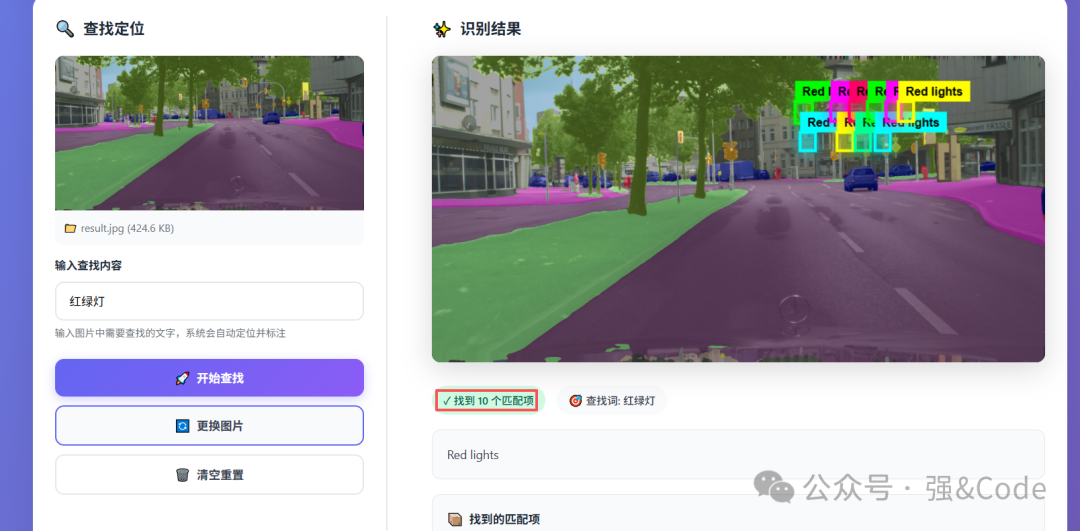
4.2 图像描述功能
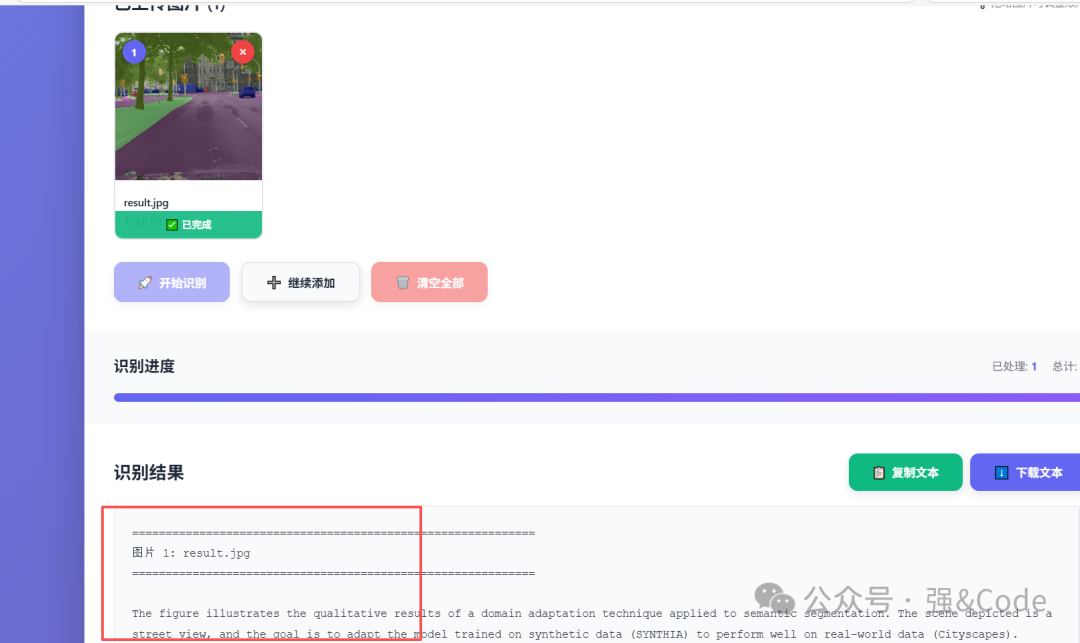
图片描述结果输出的是英文,但是整体描述的还是很强大的。
其他的我就不测试了,大家想试的话可以亲自部署体验一下。

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://www.kinber.cn/post/6104.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: